 Botond Vitos, PhD
Botond Vitos, PhDBotond Vitos, PhD is responsible for maintaing our API. He first started collaboration with our Digital Music Observatory and its trustwrothy AI project.
As data engineer, what type of data do you usually use in your projects?
Coming from a cultural studies background, my main research interest has been grassroots music scenes and festival cultures, which I hope to extend to my current projects as data engineer and as a data scientist. My prior research’s scope was mainly qualitative and focused on the inside views and stories of scene participants and stakeholders, which was invaluable in the understanding of specialized stylistic vocabularies. At the same time, I was interested in the “bigger picture,” which can be approximated through algorithmic approaches and data analysis. With both interests together, I shifted towards data science and engineering.
](/media/img/streaming/listen_local_SK_EN.png)
I was recently involved with the development of a classification algorithm that detected stylistic directions within the music genres of electronic dance music labels found on Bandcamp. The Bandcamp Librarian project makes use of the genre taxonomy offered by the industry website Beatport, which is a very top-down approach on electronic dance music genres, often resisted by the artists themselves (many of the more niche subgenres don’t even appear on the Beatport site). Accordingly, the project defined genre clusters within each Bandcamp label, which show up as combinations of Beatport subgenres. Also, it indicated some of the folksonomies (bottom-up stylistic definitions and tags) propagated by the musicians themselves.
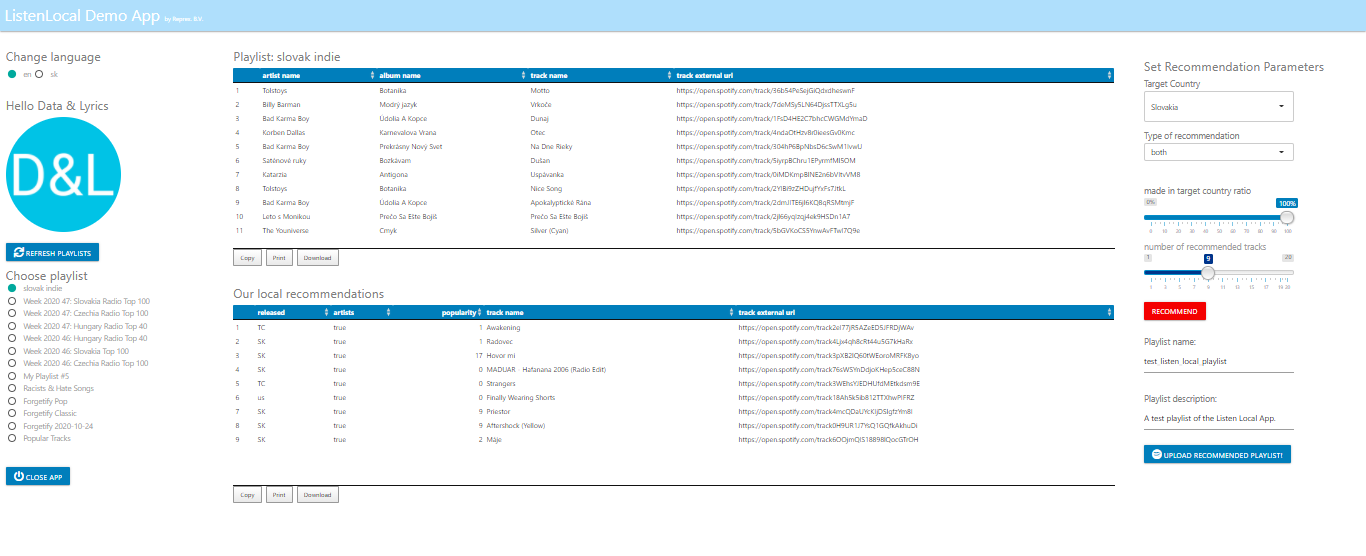
In addition, working with Reprex, I became involved in the development of the Listen Local initiative. The system was aimed to protect the rights of small local artists by offering recommendation algorithms that prioritize local talent for consideration and enables the user to find local talent. The current playlist recommendations of streaming industry giants, such a,s Spotify prioritize big labels and big names, blocking access to the output of smaller, local musicians. Naturally, I looked at this project as a possible continuation of my previous work, and we are currently extending the scope of the Bandcamp Librarian to fit this initiative.
In an ideal data world, what would be the ultimate dataset or datasets that you would like to see in the Digital Music Observatory?
As my answer to the previous question suggests, my main concern is the development of a trustworthy AI framework. Acknowledging the national and cultural diversity of the European Union, it is essential to enable access to data that takes into account such diversities and the priorities of smaller stakeholders as well. This type of data needs to be comprehensive and well-maintained, and I believe that with curators' priorities and the development of an easily accessible, open API, we are moving in the right direction.
 contains rich processing and descriptive metadata besides our high-quality indicators.](/media/img/observatory_screenshots/GDO_API_metadata_table.png)
Read More on Data & Lyrics
Join us
Join our open collaboration Green Deal Data Observatory team as a data curator, developer or business developer. More interested in antitrust, innovation policy or economic impact analysis? Try our Economy Data Observatory team! Or your interest lies more in data governance, trustworthy AI and other digital market problems? Check out our Digital Music Observatory team!
Botond Vitos
Data scientists and developer
Botond is a data scientist and cultural studies scholar with an interest in digital humanities, music research and festival cultures.